API components overview
The internals of mml may appear deeply intertwined at the beginning. The following figure shows the main components
that interact with each other during a standard experiment.
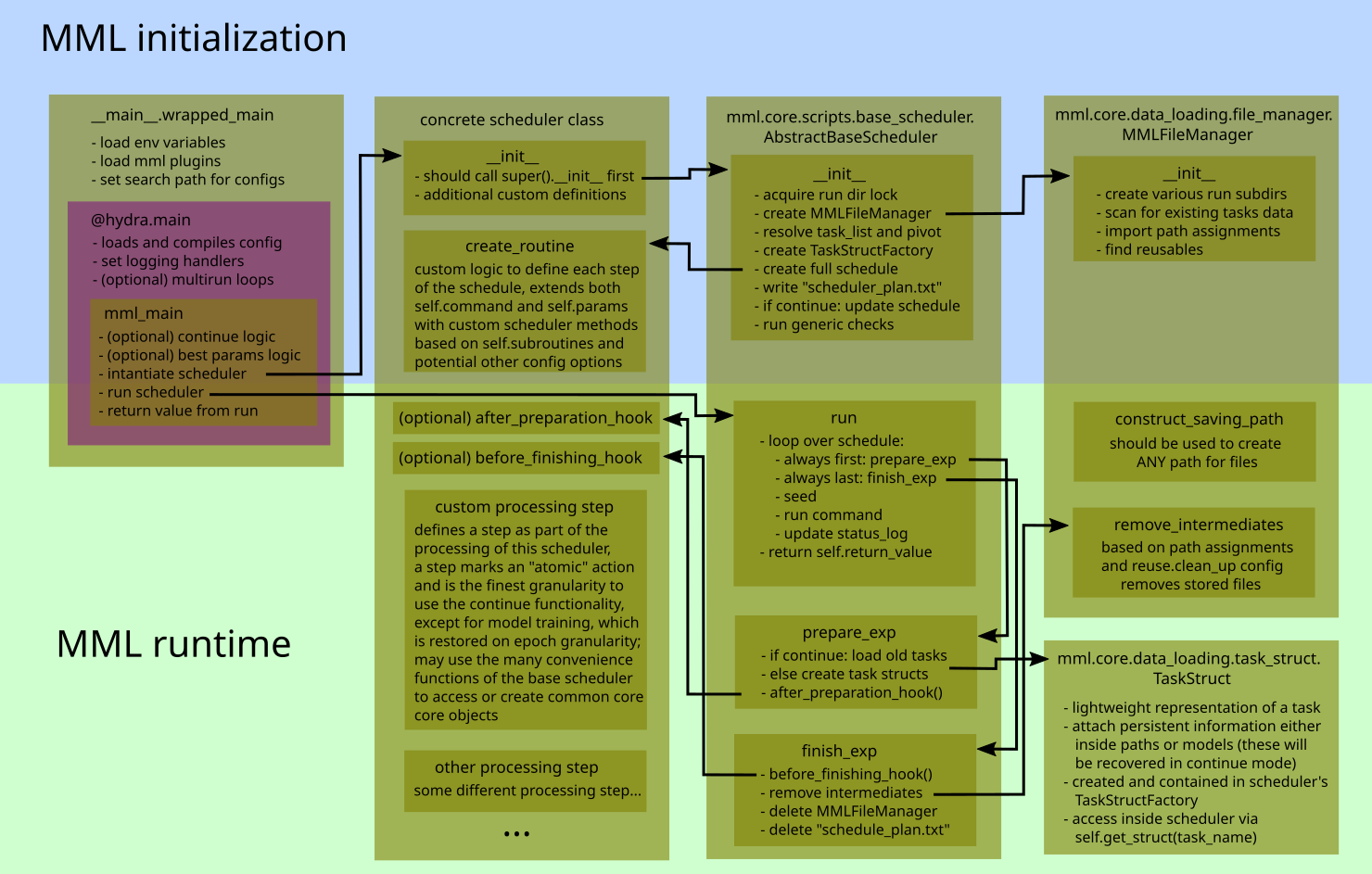
For full mml-core internals see mml-core API. For an overview on plugins see plugins.
The following quickly introduces the shown core components.
scheduler
The scheduler determines the single steps each experiment runs through. It is determined by the
mode.scheduler._target_ entry of the compiled hydra config. A sample entry would be
mml.core.scripts.create_scheduler.CreateScheduler. The main loop instantiates the referred scheduler and hands over
the config. Internally the scheduler creates all other required objects (more precisely this is handled by
AbstractBaseScheduler). Usually inherited scheduler implement the following
an
__init__, callingsuper().__init__()providingcfgandavailable_subroutinesan
create_routine, where based onself.subroutinesbothself.commandsandself.paramsare extendedoptionally the
after_preparation_hookandbefore_finishing_hookmay be overwrittenmethods that reflect the actual data processing and are added to
self.commandswithincreate_routine
These methods should reflect “atomic” steps in the processing (e.g. training of a single neural network), but not mix
multiple processing steps (e.g. training and prediction). The underlying idea is that
AbstractBaseScheduler keeps close track on the progress and may, if interrupted
during runtime, restart at the very atomic processing step the interruption happened. This continue functionality
is described in more detail in Getting started. The run()
method will iterate over all entries of commands and call
them with the corresponding parameters listed in params.
Within those steps various convenience methods and attributes of
AbstractBaseScheduler can be used:
get_struct()returns aTaskStruct
create_trainer()returns aTrainer
create_model()returns amodel
create_datamodule()returns adatamodule
lightning_tune()can tune learning rate and batch size of a model
cfgallows access to the compiledconfig
fmallows access to the currentMMLFileManager
pivotis an (optional) prominent task within the current task list
return_valuerepresents the value that will be returned once the scheduler run all commands
A consequence of the “atomic” character of scheduler methods is the necessity to store intermediate results as files, to
be persistent after a crash and reusable with continue flag. The paths to these files should be attached to the
TaskStruct via the paths attribute (except for models). See below
for more details.
file manager
The MMLFileManager is a Singleton and
may at any time be accessed via instance() once it has been
initialized during AbstractBaseScheduler’s
__init__(). The file manager is the main interface for
reading and writing files within mml. It is responsible to detect all installed tasks of mml and read in the
respective .json task descriptions to create the corresponding TaskStruct.
It’s main access within scheduler’s custom methods is via
construct_saving_path() which should ALWAYS be used to
generate saving paths for objects. Templates for the construction of such paths are provided via
add_assignment_path() which is a class method and can and should
be called before the file manager initialization. If declared as such these paths can be reusable and shared / loaded
from other projects via mml. For details of this reuse functionality see Getting started.
A lot more magic from MMLFileManager is happening under the hood of
mml. One example is the clean_up functionality. Assume that specific kind of intermediate files are not
necessary any more after a full run from the scheduler. Setting e.g. reuse.clean_up.parameters=true automatically
deletes all files of type parameter that have been created during the experiment after successful finish. Note that
lightning checkpoints of model training and all files of type temp are deleted automatically.
task struct
A TaskStruct is a lightweight representation of a task. It stores high
level information as e.g. task_type and
num_classes. Furthermore is is used to attach intermediate results
of scheduler methods via paths and
models. The former is a dictionary holding flexible string to
paths associations and the latter is a list of all trained TaskStruct for a task from scheduler’s
cfg.task_list is achieved via get_struct().